Inference on Predicted Data (IPD)
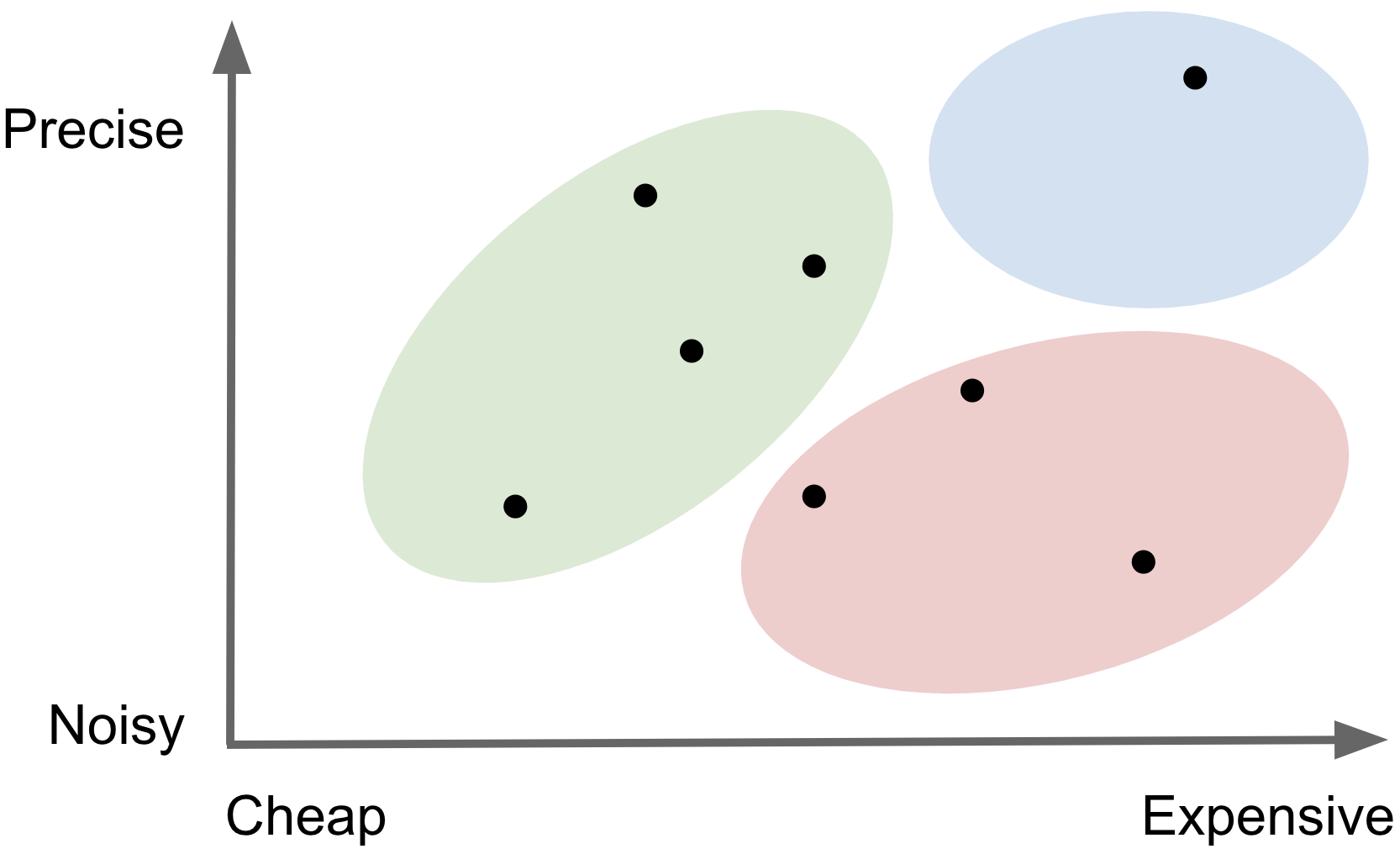
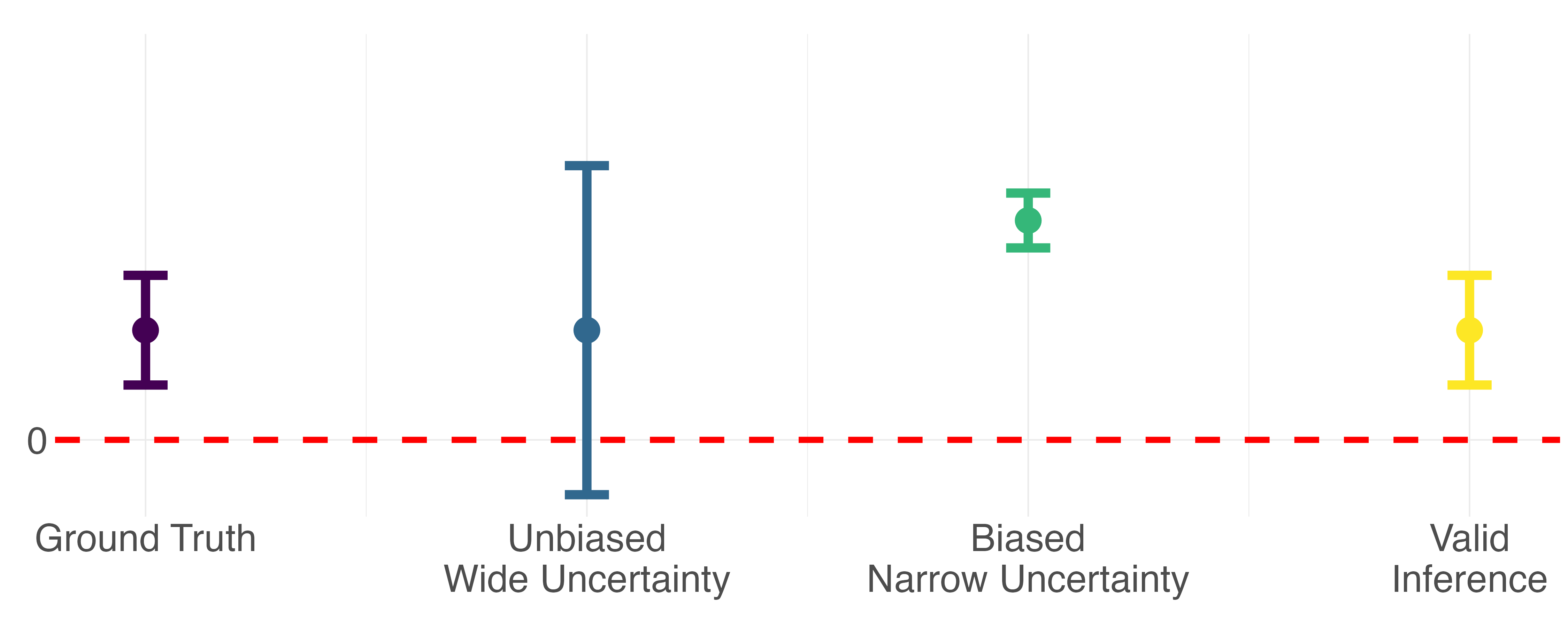
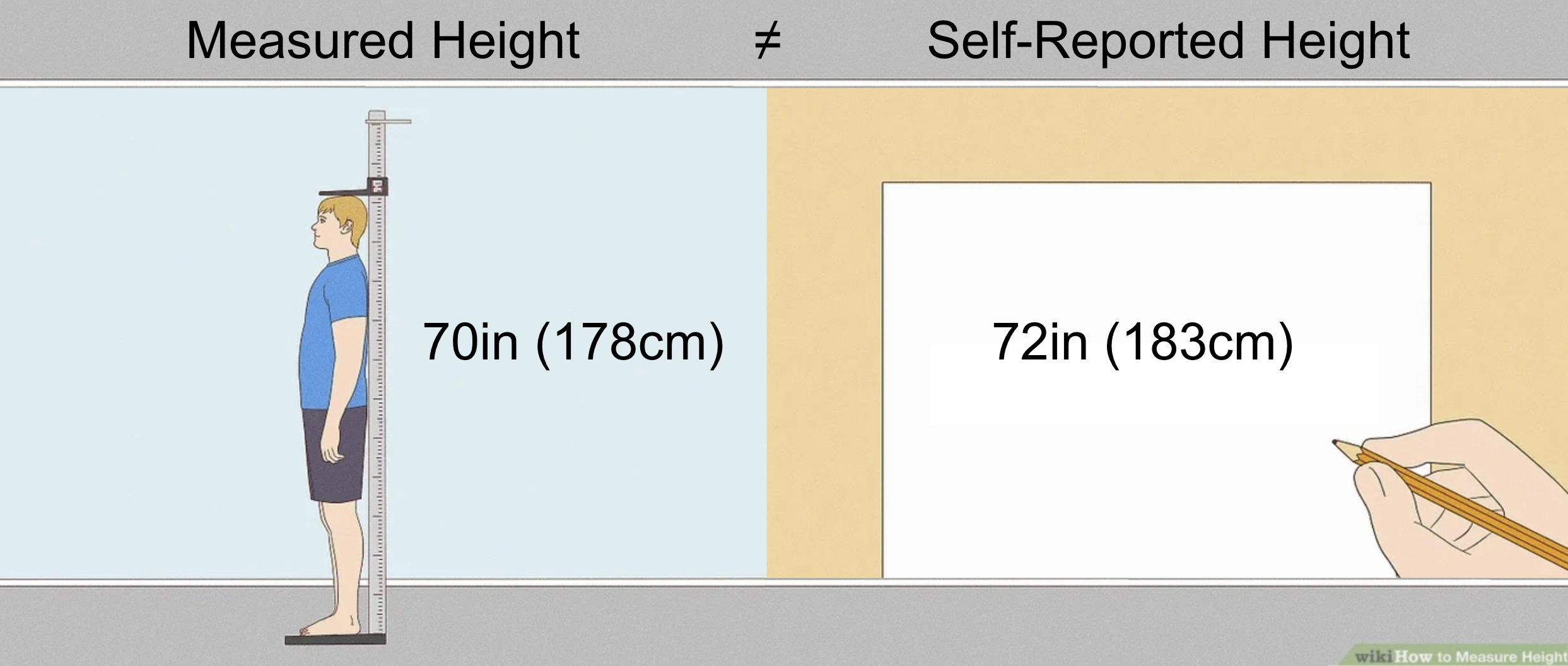
The problem: a researcher is interested in studying an outcome, Y, which is difficult to measure due to practical constraints such as time or cost. But they do have access to relatively cheap predictions of Y. They hypothesize that Y is associated with X, a set of features which are easier to measure. Their goal is to estimate a parameter of scientific interest, θ, which describes the relationship between X and Y. How can the researcher attain valid estimates of θ relying upon mostly predicted outcomes of Y?Regression we want is Expensive but Precise → Y = θ1 X
Regression we have is Cheaper but Noisier → Ŷ = θ2 X
Importantly, θ1 is not the same as θ2!
Rhinoceros analogy from Hoffman et al. 2024.